Why RAG is not enough?
Last year, I built a knowledge bot POC that had this written on the landing page.

Wombot landing page
At the time, I was aware that function (tool) calling was something that could address these limitations. However, since RAG was commoditizing quickly, we halted the exploration and looked at off the shelf solutions.
Fast forward to a year, I attended the Microsoft’s AI tour1 to see what they’re up to and was glad to see that knowledge bot ecosystem has well defined solutions for all these limitations.
Before looking at the solutions, let’s understand these limitations.
What most knowledge bots do?
- Most knowledge bots use RAG (Retrieval augmented generation), and some even add the web search results to the mix.
How will such a bot answer the following question?
Find me all the workplace themed LEED certified projects in Sydney done by design principal John Doe.
Semantic Search
How does it work?
- We take the private company documents, split their text into chunks and generate numerical vectors for these chunks using an encoder model.
- These vectors are indexed in a relational database.
- The user’s question is also turned into a numerical vector using the same encoder model.
- A similarity search is performed in the database to find the vectors that are semantically nearest to the numerical vector from the question.
- From these similar vectors, we retrieve K number of vectors and the chunks associated with them.
- These chunks along with the original question, context, and conversation history are passed to an LLM for inference.
Assuming numerical factors were generated from project information documents, the chunks returned by the semantic search may resemble the following.

Sample semantic search results
While all of them are semantically relevant, not all of them are helpful.
Chunk 3 is only a partial match. While not led by John Doe, this project demonstrates similar sustainability practices in workplace design.
Chunk 5 is a distractor. Although certified under LEED, this project is a residential development and not categorized as workplace.
Web search
Here, the bot is going to try to find the information from the blogs, company website, public project directories, green project databases, etc. And the results may resemble the following.

Sample web search results
Here, Green design weekly, is an example of an irrelevant web result.
Limitations of RAG
When these chunks and web results are passed to an LLM, it will be able to give you a list of projects. However, we don’t confidently know if the bot was able to find all the projects that met the criteria mentioned in the question.
What if, instead of seeking to get the names of all the projects, the user sought to know the total number of projects that met the criteria mentioned in the question. In this case too, while the bot may fetch the similar information, we will not have the confidence in the number it will report.
Lastly, imagine asking this bot the following question
What are the average man hours spent on workplace projects in 2025 Q1 at company X?
Since the question involves fetching relevant data and performing some computation on top of that, the bot will most likely not able to answer this question.
As more and more businesses are experiencing these limitations, the ecosystem has come up with some solutions.
Advanced Search Strategies
- Most knowledge bots use RAG + internet search to handle all types of queries.
- The limitations of these bots can be addressed by using techniques specific to query types.
Simple queries
- A query is simple when it mostly consist of a single question.
- It typically does not involve
- Multiple questions
- Data aggregation
- Data filtering
- Further computation on gathered results
Keyword Search
- Best for exact phrase matches
- Builds an inverted index from the documents using algorithms such as BIM25 and others.
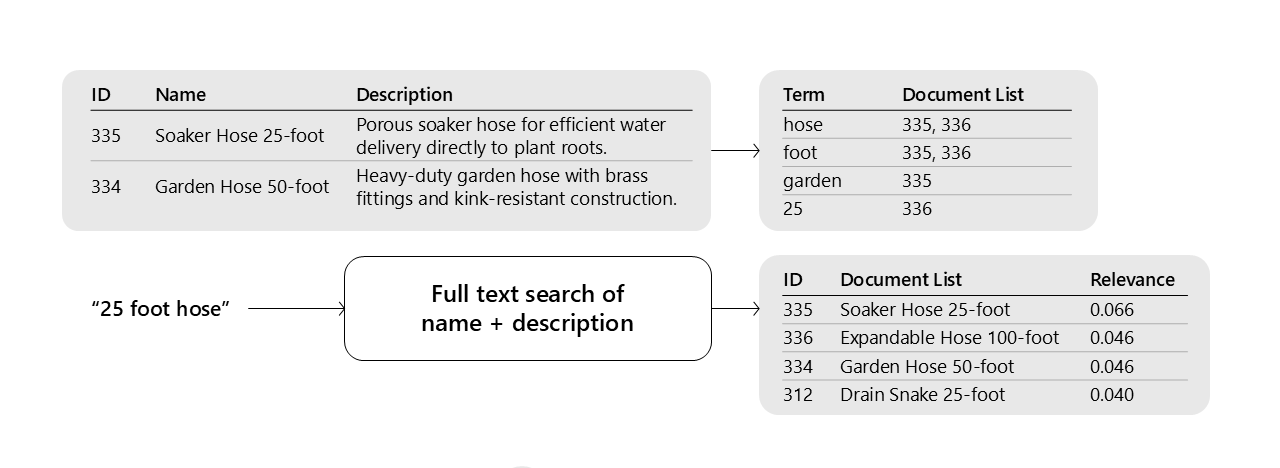
Image source: Microsoft AI tour presentation
Think of inverted index as a HashMap where a word is mapped to an array of document ids it appears in.
inverted_index = {
"25": [1, 3, 5],
"foot": [0, 1, 2, 3, 5],
"hose": [5]
...
}
Vector Search
- This is something that most RAG bots already do.
- Great for conceptually similar searches.
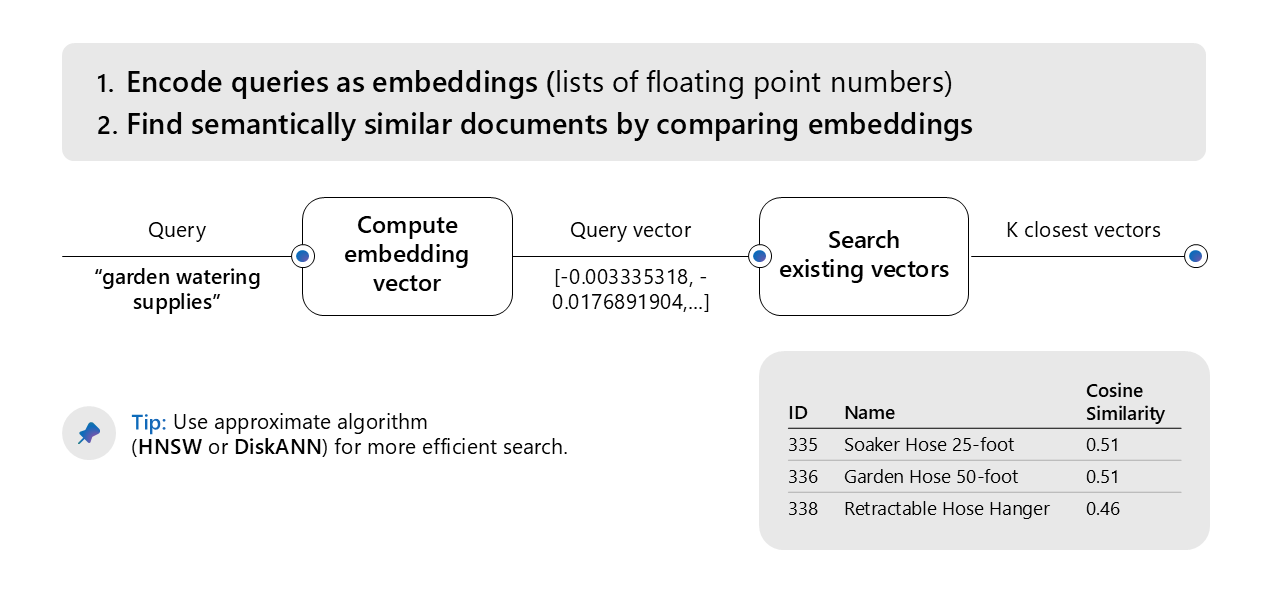
Image source: Microsoft AI tour presentation
Reciprocal Rank Fusion (RRF)
Merge the results from the keyword search and the vector search and rank the results based off their relative ranks.
Image source: Microsoft AI tour presentation
Re-Ranking
- Use a specifically trained ranker model to give documents a relevant score according to the query.
- Cross-encoder models like Cohere ranker are best, but LLMs can be used as well.
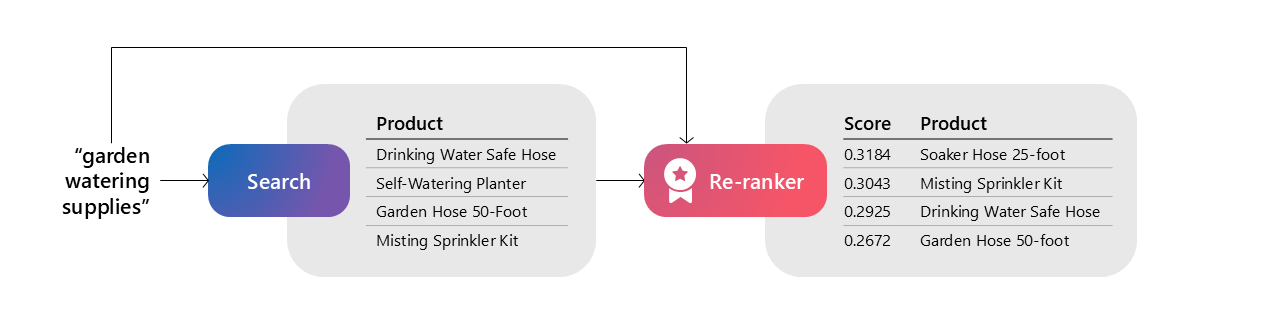
Image source: Microsoft AI tour presentation
It has been observed that for most queries, the hybrid approach outperforms either just RAG, or just keyword search.
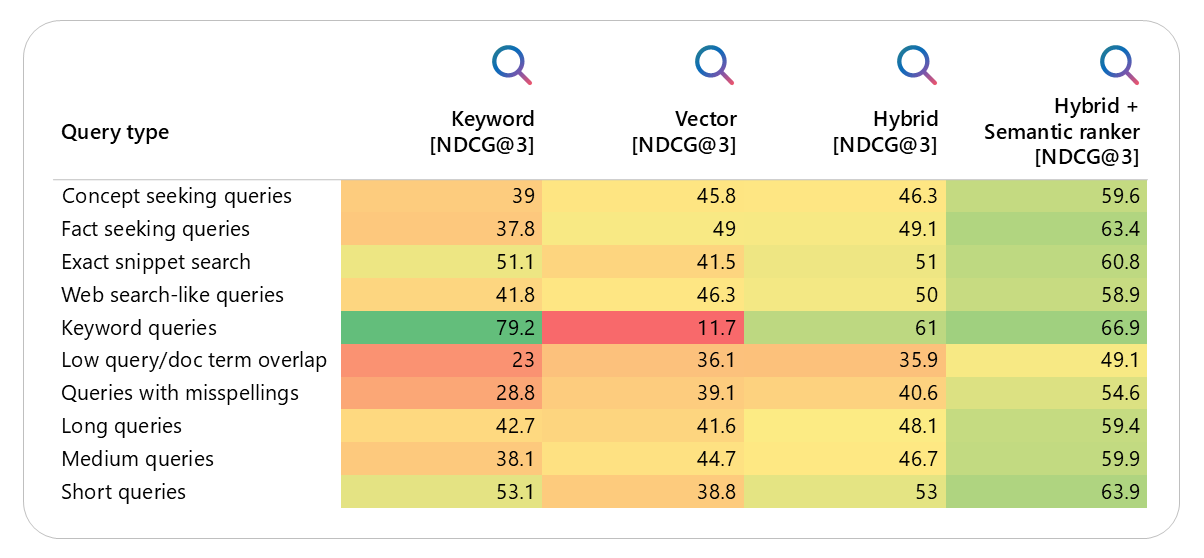
Image source: Microsoft AI tour presentation
But hybrid search is not always enough. How do you handle more complex types of queries?
Relational Queries
When your query involves relations. For example,
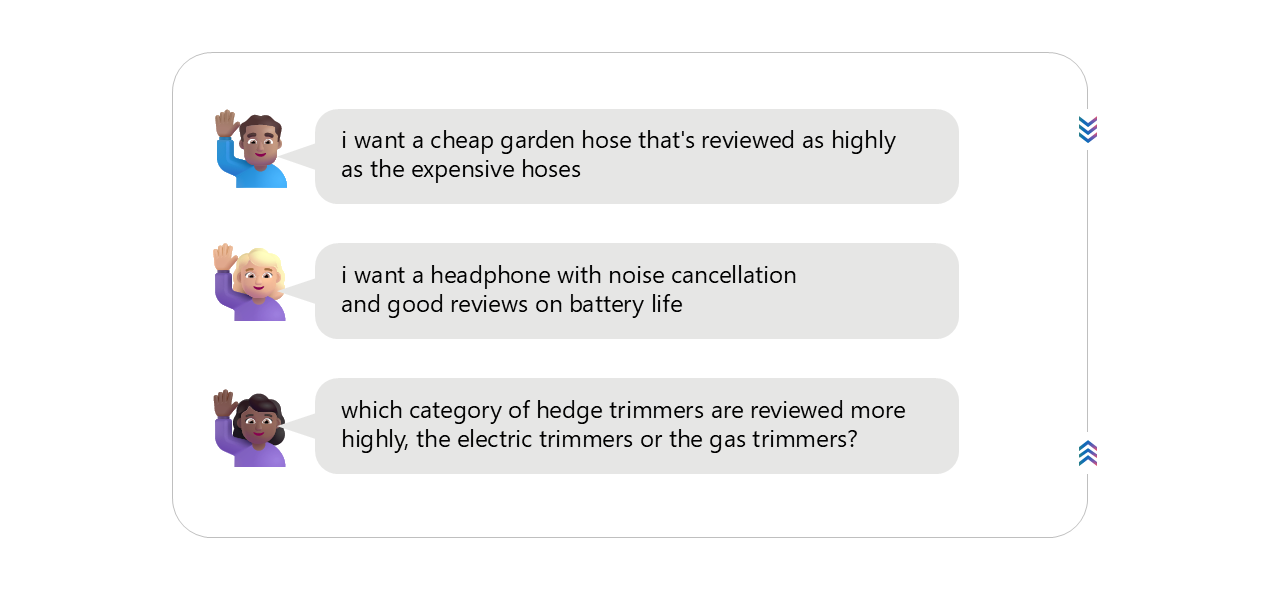
Image source: Microsoft AI tour presentation
Here, we can use the LLM to come up with a Graph or an SQL query to run on our Graph or a relational database respectively.
The modern LLMs are becoming increasingly better at translating a user query into an SQL or a Graph query given the context and the database schemas.
Using this approach assumes that the company is at at least the state-12 of the data maturity journey.
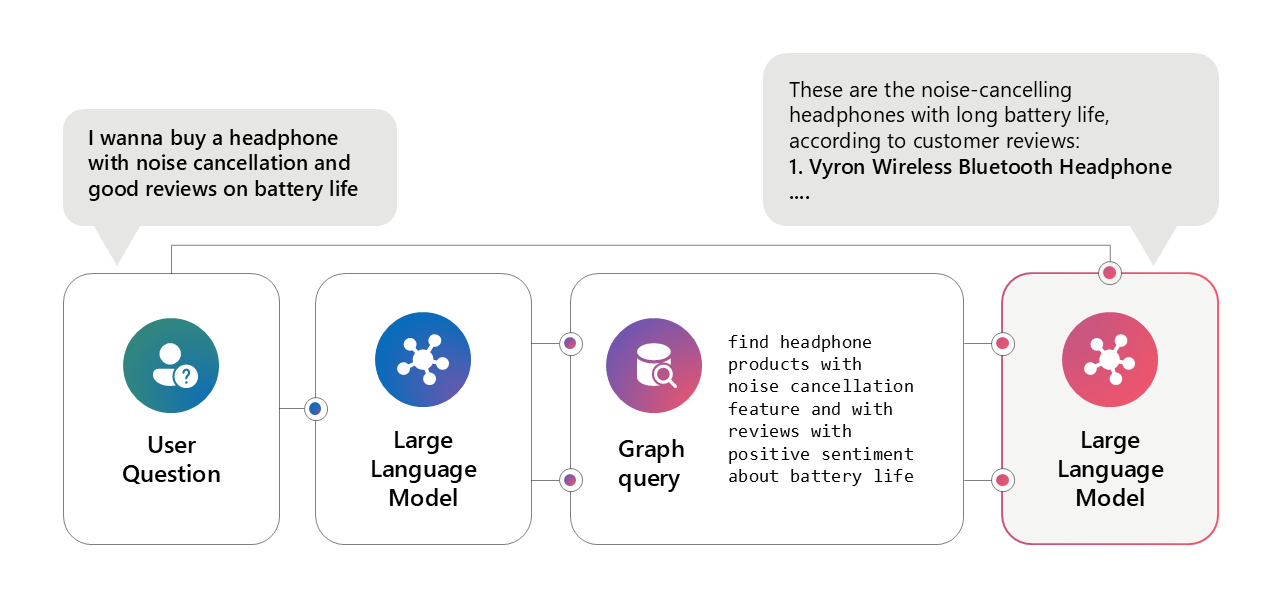
Image source: Microsoft AI tour presentation
Multiple Queries in One
When a query involves multiple queries. For example,

Image source: Microsoft AI tour presentation
This is where the search start becoming agentic and the idea of query planning comes into play.
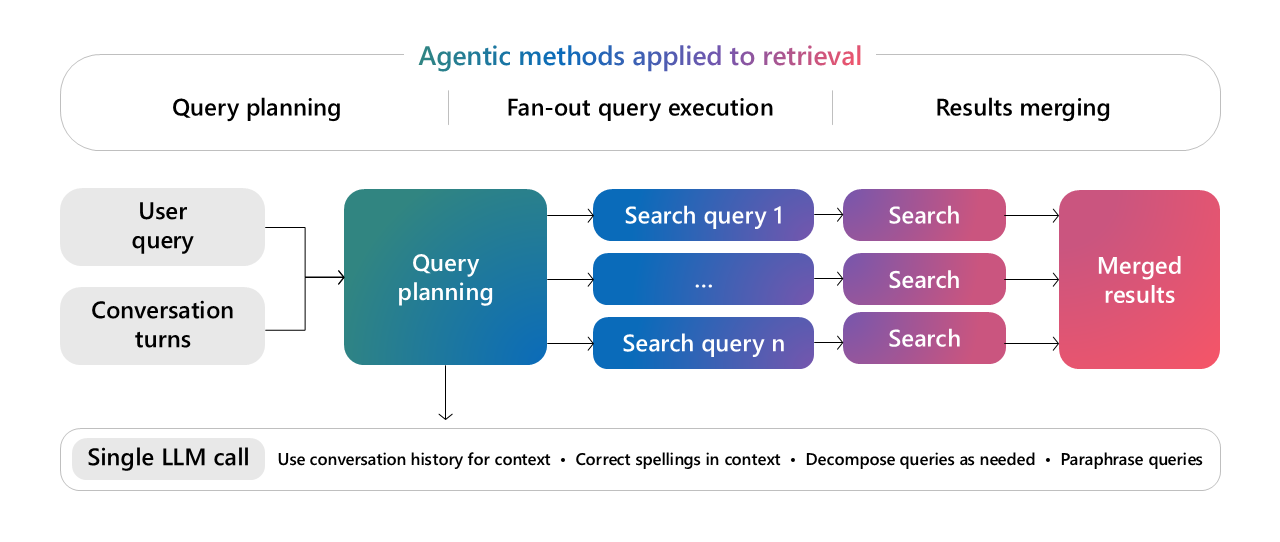
Query planning3
- The LLM breaks down a complex query into smaller, focused subqueries.
- These subqueries can be
- A hybrid search
- A web search
- A relational search
- The LLM runs the queries in parallel
- Combines the results
- Ranks them based on the original query
- Finally, a uniform response is provided to the client (user).
Image source: Microsoft AI tour presentation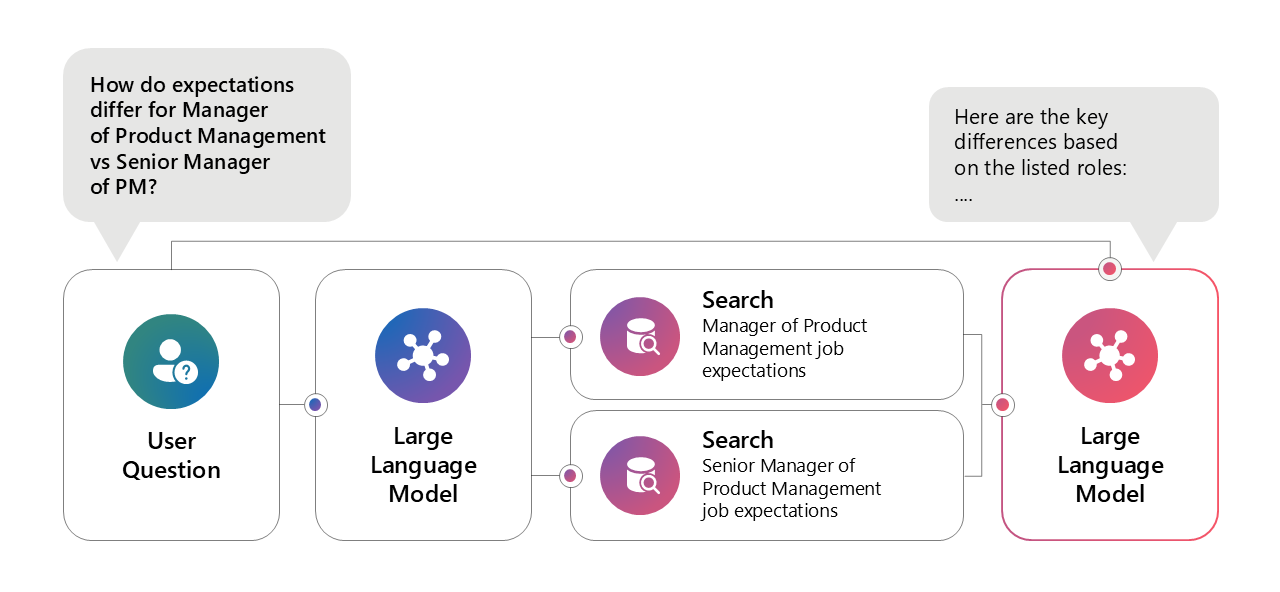
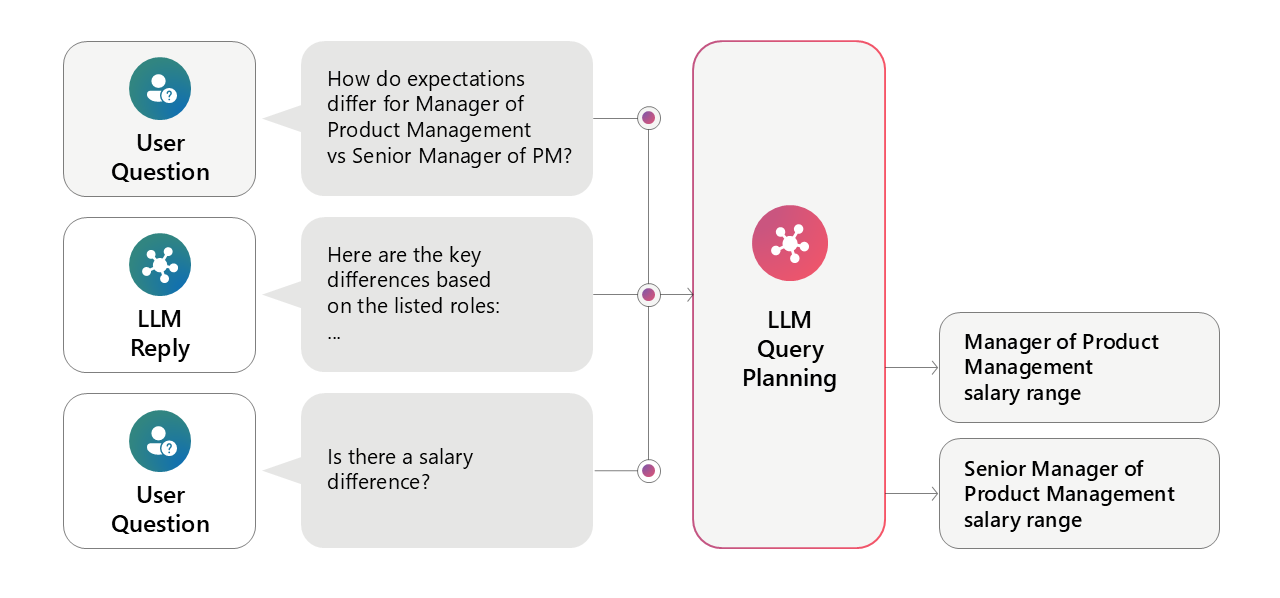
Managed Search Solution
Interesting to see that the Azure AI search offers all of this as a managed service4. Where you are only responsible for
- Bringing your data
- Building your clients
The rest of the heavy lifting involving
- Building and updating database indexes,
- Query planning Is done by a managed service.

Image source: Microsoft AI tour presentation
Making Search Cheaper
Prompt engineering is used to add a character (personality) to a chat bot. Here, a guideline in the form of text is provided to the chat bot in terms of
- What should be the length of the response?
- How it needs to format the response
- What kind of tone it needs to use in the response
But one major downside of this practice is that you are paying for the additional tokens in all the conversations. Such costs can add up quickly when users are having multiple conversations throughout the day across the organization.
How to use fine tuning to make search cheaper?
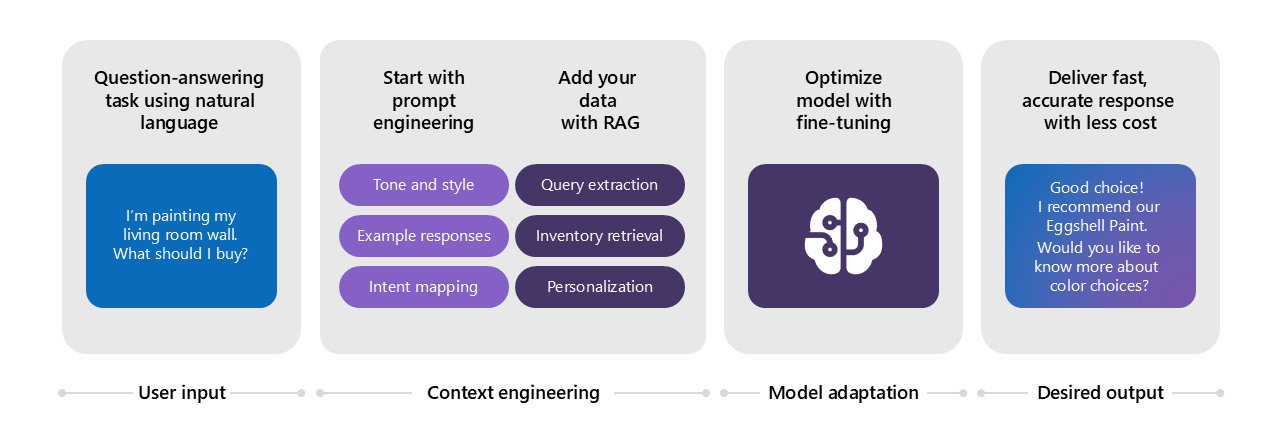
Image source: Microsoft AI tour presentation
What is fine tuning?
- It refers to customizing a pre-trained LLM with additional training on a specific task or new dataset for enhanced performance, new skills, or improved accuracy.
- This dataset could take many forms.
- In the context of training for tone, the dataset could be input-output pairs or instructions and desired responses.

Image source: Microsoft AI tour presentation
Fine tuning can also be useful to add often private domain specific knowledge such as project proposals (bids), and for task-specific optimization such as Grasshopper or Dynamo workflow generation.
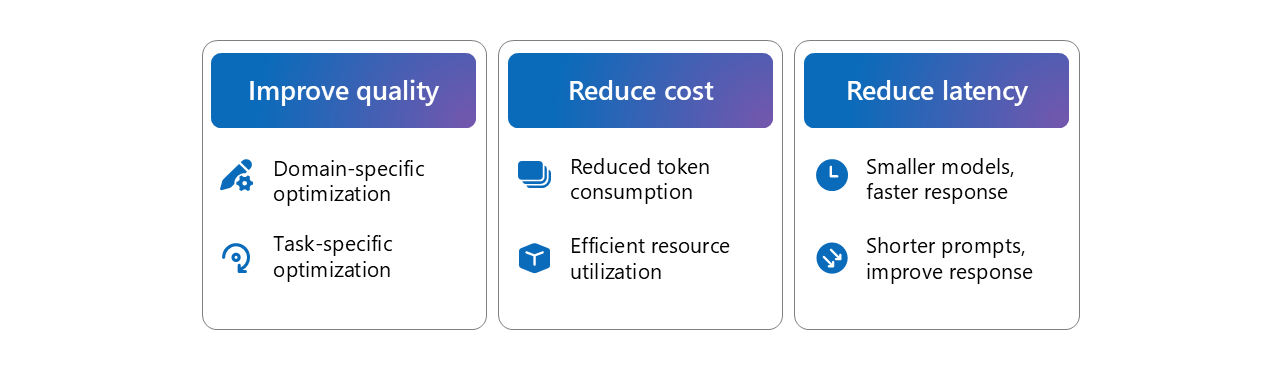
Image source: Microsoft AI tour presentation
There are several fine tuning techniques to choose from.
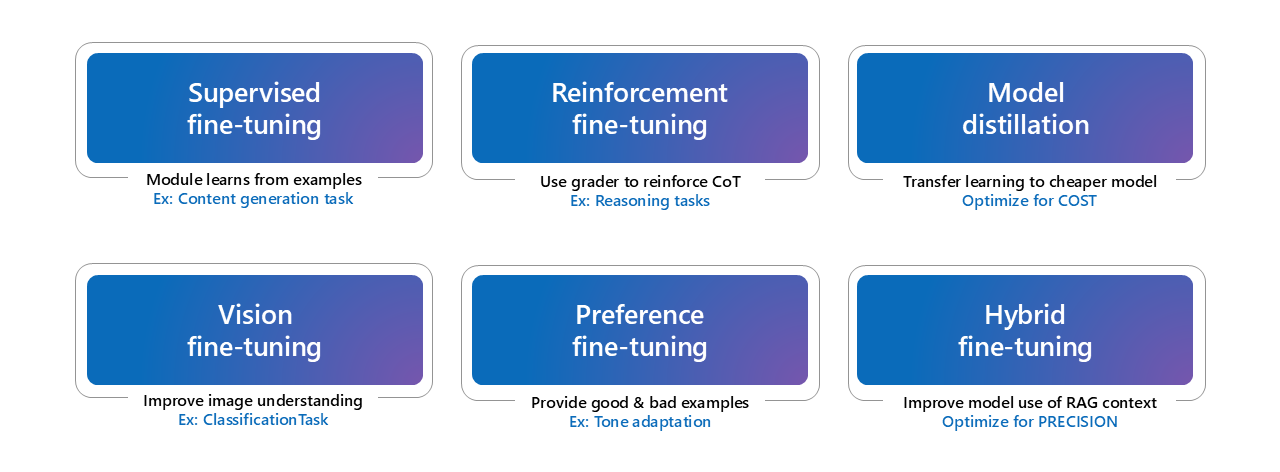
Image source: Microsoft AI tour presentation
Increasingly, organizations are moving incorporating fine tuning in their workflows.
Image source: Microsoft AI tour presentation

Example of getting to the point answers with improved accuracy using RAFT. Image source: Microsoft AI tour presentation
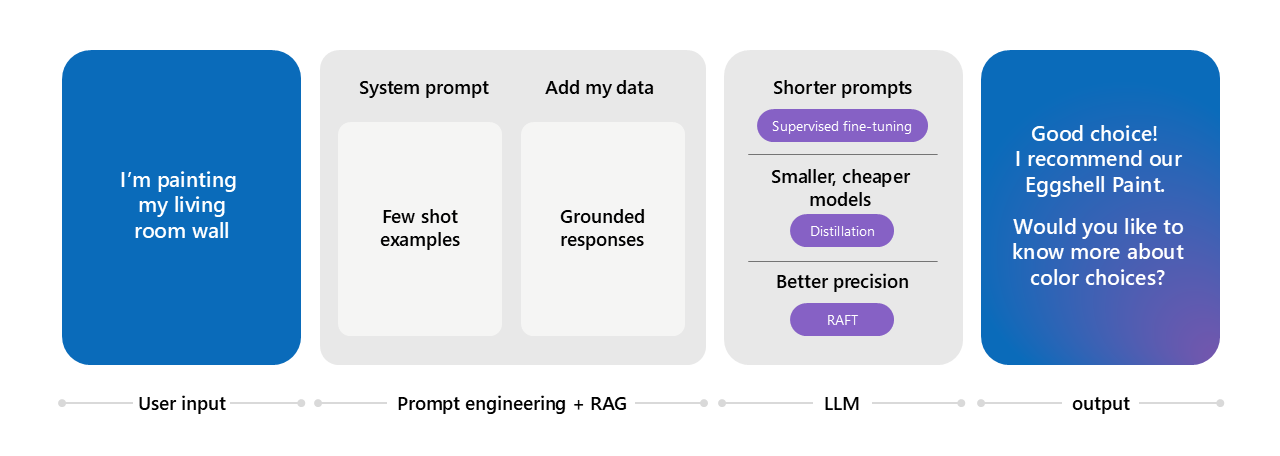
Is RAFT for everyone?
While RAFT is touted to improve the experience and accuracy of knowledge retrieval, organizations must realize the initial investment in terms of human hours and money required incorporate fine tuning in their workflows. Image source: Microsoft AI tour presentation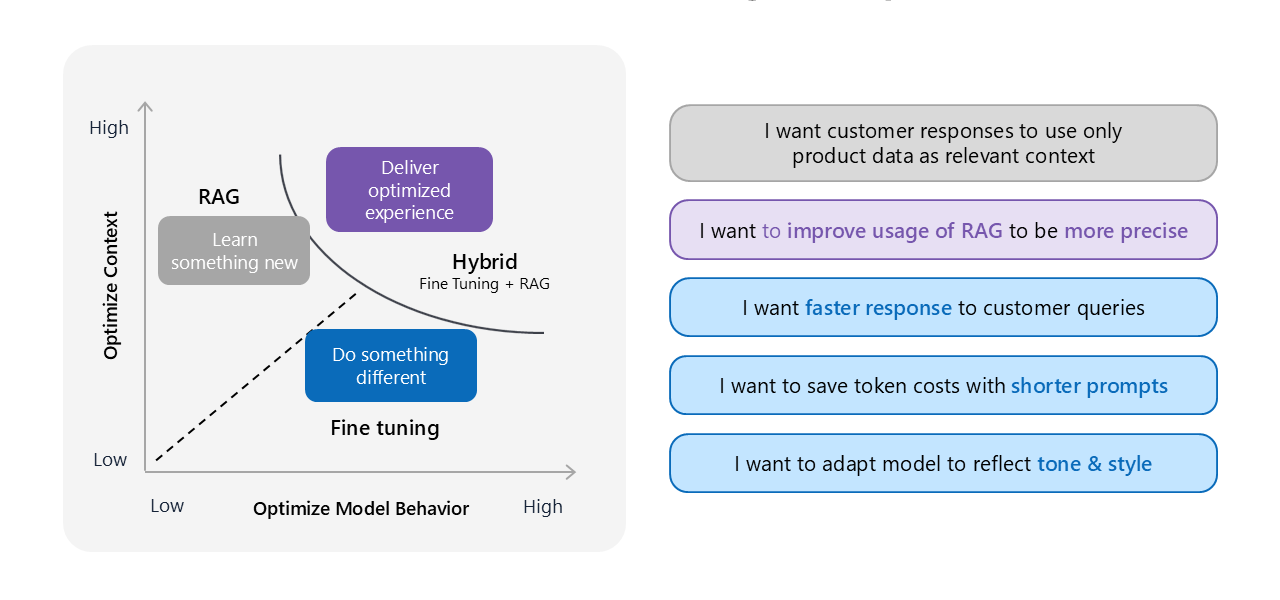
It’s a cyclical exploratory process where you start with data, choose a technique, fine tune a model, and evaluate the results. This may take several iterations and may involve changing the fine tuning techniques and hyperparameters multiple times. Image source: Microsoft AI tour presentation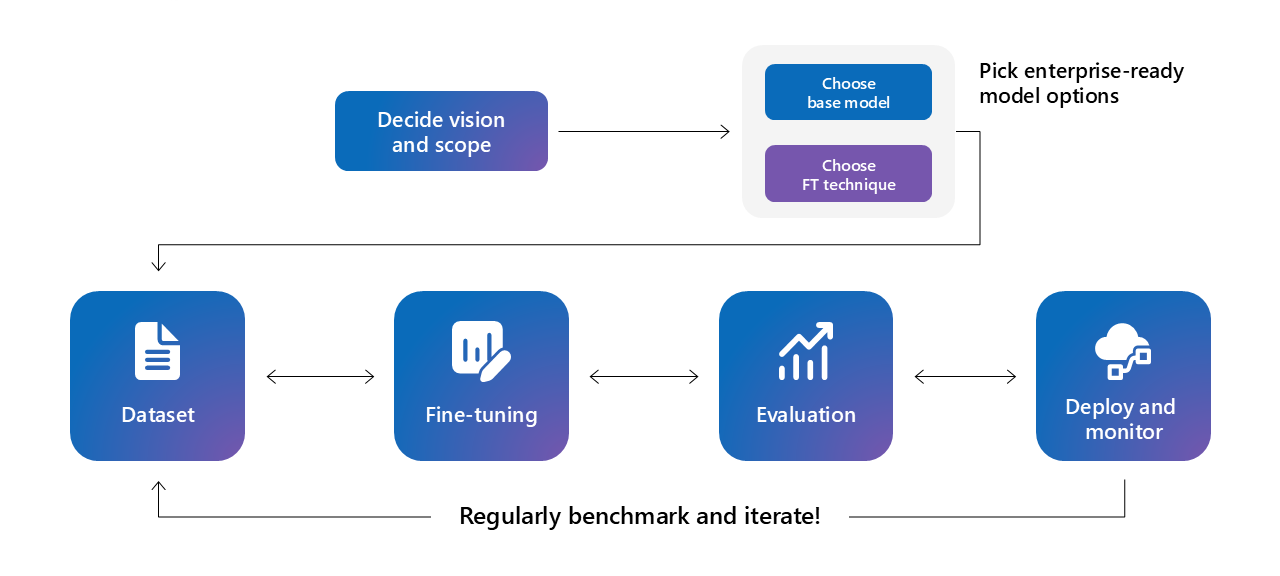
Closing thoughts
When every year, more and more of the knowledge bot tool chain is being commoditized, where do we focus our efforts on?
- It seems to be on the private data we hold as an organization.
- Extracting and getting this data in a shape to be consumed by these knowledge retrieval pipelines seem like a high leverage activity.
https://aitour.microsoft.com/flow/microsoft/toronto26/sessioncatalog/page/sessioncatalog ↩︎
https://pipeline2insights.substack.com/i/150965082/stage-starting-with-data ↩︎
https://learn.microsoft.com/en-us/azure/search/agentic-retrieval-overview#:~:text=to%2Dagent%20workflows.-,Here%27s%20what%20it%20does,-%3A ↩︎
https://learn.microsoft.com/en-us/azure/search/search-what-is-azure-search ↩︎